
随着深度学习模型参数量及数据量的快速增加,模型训练对算力的需求快速上升,构建超级人工智能算力系统成为重要课题。单gpu芯片的性能提升速度受到先进制程等限制逐步放缓,互连技术成为提升算力系统性能的重要手段。互连技术的核心目标是将更多的计算核心扩展成高性能的数据中心,并在此过程中降低性能损耗。英伟达作为gpu领域的绝对龙头企业,在构建ai算力的工程方案和技术探索方面一直处在行业前沿。本文深度研究英伟达的算力互连技术路线,并梳理产业发展趋势,发掘相关机遇。
一、构建超级ai算力的必要性及挑战
自2023年以来,chatgpt的问世掀起了新一轮的人工智能热潮。随着模型参数量的增加,模型训练对算力的需求也呈指数级上升,提供高性能ai算力的gpu供不应求。为更好地满足模型训练对算力的需求,以英伟达为代表的gpu厂商不断提升产品性能,一方面提高单gpu芯片算力,另一方面则尝试构建包含更多gpu单元的巨型算力系统。
单芯片算力的提升高度依赖上游的半导体制造工艺的迭代,发展趋缓。单gpu芯片的算力与流处理器(streaming multiprocessor,sm)的数量相关,若工艺制程不变,则芯片的面积越大,晶体管的数量越多。然而,随着摩尔定律发展放缓,增加单芯片晶体管数量的难度与日俱增。以英伟达的最新一代blackwell芯片为例,其尺寸已经达到整块晶圆在光刻机曝光极限下所能支持的最大面积,即800平方毫米 。继续增加面积不仅需要改进光刻掩膜技术,晶圆也会由于超越物理极限而易于断裂,且生产良率会因缺陷增加而下降。诸多限制使得提升单芯片算力极具挑战,有效地将更多算力芯片通过互连技术组合成算力系统成为重要议题。
构建多gpu算力系统需要克服多芯片互连带来的性能衰减问题。比如,使用8个gpu进行模型训练通常只能获得4~5倍的速度提升,而不是理想中的8倍。造成性能衰减的主要原因有:一是gpu之间的通信开销,即随着gpu数量的增加,数据同步和梯度聚合所需的通信量也会增加,这会导致严重的性能瓶颈;二是传输系统带宽限制,传统的pcie接口在多gpu系统中往往无法提供足够的带宽,特别是需要频繁交换大量数据的深度学习任务时;三是gpu同步开销,在多gpu训练中无论是采用何种并行方式,计算单元之间都需要频繁进行参数同步,导致计算资源浪费;四是gpu负载均衡,如果没有合适的互连技术和调度策略,可能会导致某些gpu负载过重而其他gpu闲置,影响整体效率。
为解决上述问题,开发者不断探索各个层面的算力互连方案,以连接更多的gpu核心并尽量减少芯片互连带来的性能衰减,实现接近线性的性能提升。英伟达作为加速计算领域的绝对龙头,在ai算力领域的市占率超过80%,在构建ai算力的工程方案和技术探索方面也一直处在行业前沿。研究英伟达的技术路线可以帮助我们更好地理解产业发展趋势,并发掘相关投资机会。
二、英伟达算力互连技术路线梳理
英伟达创始人黄仁勋曾表示,公司实现超级ai算力的工程思路是将算力设计分成四个物理层面,并分别进行优化:一是单gpu芯片的算力提升;二是芯片内的互连;三是芯片间的互连;四是多机柜互连。可以发现,单gpu芯片的算力提升仅是其中一环,其余几个层面的优化均依赖相应的算力互连技术。
(一)芯片内互连
基于先进封装技术实现的各类chiplet架构是最小物理层面的“互连”。随着摩尔定律趋近极限,行业普遍认为chiplet架构是未来5年算力提升的主要技术之一。
英伟达于2024年3月的gtc大会发布了gb200 gpu,将其称为“超级芯片”。gb200由两个第五代架构的blackwell芯片b200和一个基于arm架构的grace cpu组成,在使用fp4(4位浮点)数据单元进行人工智能推理任务时可输出20 pflops的算力,较上一代产品h100实现了约5倍的性能提升。gb200搭载的sm(流处理器)数量为h100的4倍,其中,b200芯片较h100的面积提升贡献了2倍sm数提升,而通过chiplet架构将两个b200连接则贡献了另外2倍的sm数提升。
具体来说,英伟达通过nv-hbi(high bandwidth interface)技术将两个b200 gpu进行连接,构建了世界上尺寸最大的chiplet。hbi通过在板内增加贯穿的铜线,并在pcb板背面添加金属焊球导通不同位置的连线,实现了复杂结构的2.5d互连。在该结构下,芯片间的通信速度达到10tb/s,极高的片间传输速度使两块gpu在使用过程中可以等效为一块cuda gpu运行。gb200是当前在单个基底上能够实现的最先进的裸片间(die-to-die)互连方案。另一头部科技大厂苹果也拥有自主的互连技术——ultrafusion,但其片间通信速度仅为2.5tb/s,只适用于消费级电子产品。
(二)芯片间互连
大模型训练过程中主要使用了两种并行策略:一是数据并行,即在多个gpu间分布数据来实现并行处理,每个gpu都会存储模型的完整副本,独立地对其分配的数据子集进行前向和反向传播计算。二是模型并行,即在多个计算节点上分布式地训练一个大型的深度学习模型,每个节点负责模型的一部分,解决了单个计算节点无法容纳整个模型的问题。
实际计算过程中,一个gpu负责模型的一部分,同时处理不同的微批次,在节点内部对大型的矩阵运算做出进一步任务分割。多gpu系统内,gpu间通信的带宽通常在数百gb/s以上,传统的pcie总线的数据传输速率容易成为瓶颈,且pcie链路接口的串并转换会产生较大延时,影响gpu并行计算的效率和性能。
1.nvlink:专有gpu高速互连技术
为了突破异构计算场下gpu间传输速度的瓶颈,英伟达推出了nvlink。nvlink是一种总线及其通信协议,采用点对点结构、串列传输,是世界首项高速gpu互连技术,与传统的pcie系统sbobet利记官网的解决方案相比,能为多gpu系统提供传输速度更快、延迟更低的系统内互连sbobet利记官网的解决方案。nvlink一代于2014年发布,单条nvlink链路内部含有16对差分信号,发送和接收方向各有8条通道,每条通道带宽20gb/s,总带宽320gb/s。目前,nvlink已经演进到第五代,单个blackwell gpu支持18通道nvlink 100 gb/s连接,总带宽1.8 tb/s,比上一代产品提高了两倍,是pcie 5.0带宽的14倍。
2. nvswitch:跨机柜芯片间高速互连
nvswitch是nvlink技术的延伸,于2018年发布,旨在解决单服务器中多个gpu之间的全连接问题。在dgx p100架构中,8个gpu通过nvlink形成环状连接,无法完全实现点对点的连接。为了解决gpu之间通信不均衡问题,英伟达引入基于nvlink高级通信能力构建的nvswitch芯片。nvswitch允许单个服务器节点中多达16个gpu实现全互连,即每个gpu都可以与其他gpu直接通信,无需通过cpu或其他中介。目前,第三代nvswitch能以惊人的900gb/s的速度互连每对gpu,创建了无缝、高带宽的多节点gpu集群,使所有gpu在一个具有全带宽连接的集群中协同工作。
借助nvlink和nvswitch,英伟达将36块gb200组装于一个标准服务器机架,构成了搭载72个blackwell gpu核心的机柜gb200 nvl72,相较传统的8卡并联方案(如华为昇腾和amd)实现了巨大飞跃,进一步提升了英伟达产品的竞争力。一台nvswitch提供的nvlink接口为144个,而一个nvl72机柜内,需要用到9个nvswitch tray(各包含2个nvswitch芯片)以支持全部36个gb200超级芯片实现全连接。
此外,英伟达又通过添加第二层nvswitch交换芯片实现了8台gb200-nvl72机柜互连。在此场景下,通过nvlink直接互连的gpu数目达到了576个,英伟达将这8台完全互连的gb200-nvl72命名为gb200 superpod,是其数据中心业务的旗舰产品。值得注意的是,nvswitch的最大综合带宽为1pb/s,是单个nvlink的近500倍,但其最大峰值非阻塞带宽为14.4tb/s,远低于单个nvl72机柜内部的130tb/s。由此可见,在机柜层面上的性能扩展并不是无损的,在训练时,大量的通信任务集中在机柜内部,只有必需时才进行机柜间的通信。
(三)机柜间互连
在superpod架构中,不同的gpu之间通过nvswitch和nvlink实现了高速、低损耗连接,而不同的服务器节点(如多个nvl72之间)、存储设备之间则主要通过infiniband网卡和infiniband交换机连接。
infiniband是一种专为高性能计算(hpc)环境设计的高速数据传输技术,它基于远程直接内存访问(rdma)开发,并通过使用交换式结构拓扑,通过点对点通道传输数据,进一步优化了rdma的优势。infiniband非常适合需要高并发和低延迟的工作负载,如ai训练和hpc任务。
rdma是分布式训练中使用最为广泛的网络技术,允许直接远程访问内存数据,无需内核干预和cpu资源利用,它提供低延迟、高带宽的互连,使服务器、存储设备和其他计算系统之间能够快速高效地通信。相比之下,传统的tcp/ip网络通信涉及通过内核发送消息,需要数据移动和复制,不适合高性能计算、大数据分析等需要高并发i/o和低延迟的场景。目前,rdma共衍生出三种技术:infiniband、roce(rdma over converged ethernet)和iwarp(互联网广域rdma 协议),后两者是基于以太网的技术。
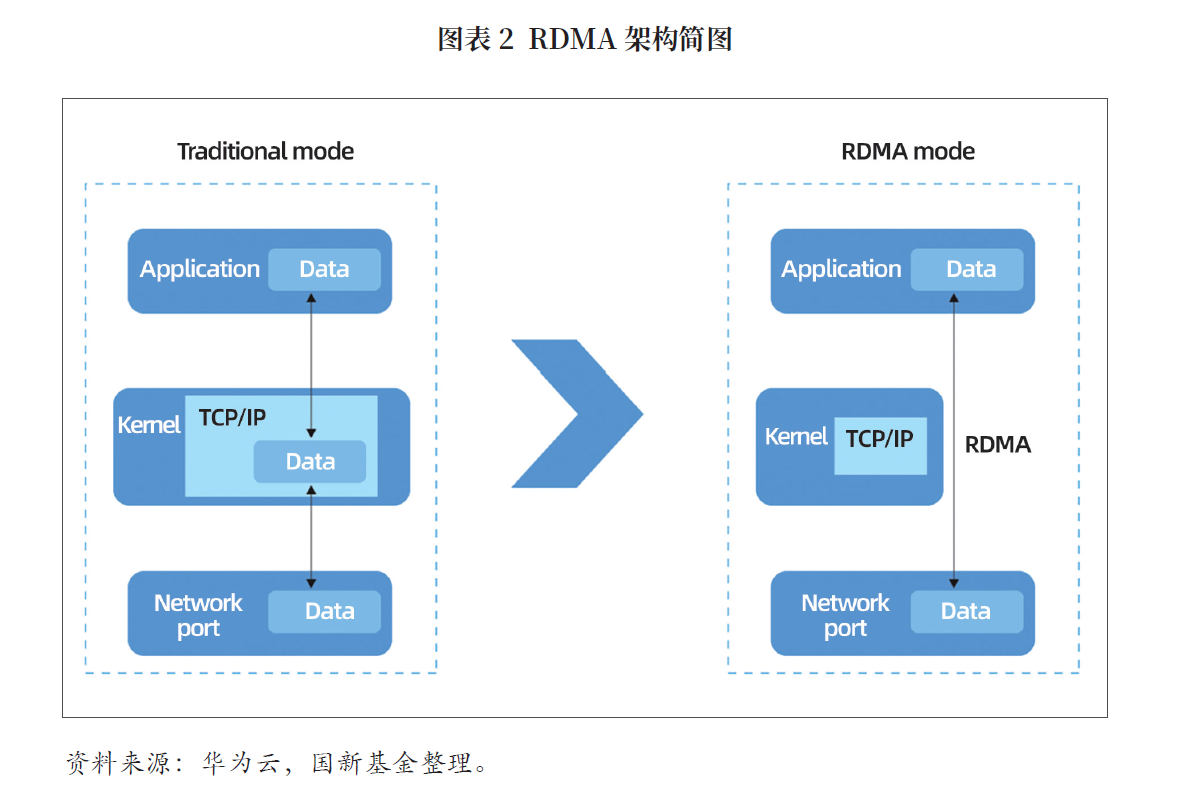
英伟达是infiniband路线的主要玩家,独家提供了相关的交换机、电缆等硬件设备,2019年以69亿美元收购infiniband和以太网交换机及网络接口卡供应商——以色列公司mellanox,构建了自己的技术生态。英伟达围绕其infiniband技术重新设计了物理链路层、网络层、传输层,推出了infiniband专用的交换机、网卡、电缆等产品,相关业务的收入在过去5年中增长了7倍。
尽管计算性能稍弱,但以太网相较于infiniband具有更强扩展性,且部署成本和功耗更低。由于英伟达基本垄断了infiniband,其他半导体厂商如amd、博通均围绕以太网开发其产品,并于2023年7月成立超以太网联盟,计划在roce v2网络协议的基础上,面向大模型这一场景,开发全新的以太网协议以对抗英伟达的infiniband。

基于以太网协议的网络兼容性、可扩展性、开放性强,作为行业领军者的英伟达在推出infiniband交换机的同时升级了以太网交换设备产品。英伟达的以太网产品spectrum-x800在spectrum-x基础上进行了升级,是行业中首个针对ai计算集群通信优化的以太网平台。spectrum-x800基于roce协议设计,具有rdma、自适应路由、可编程拥塞控制、低延迟、可见性等功能和特性。
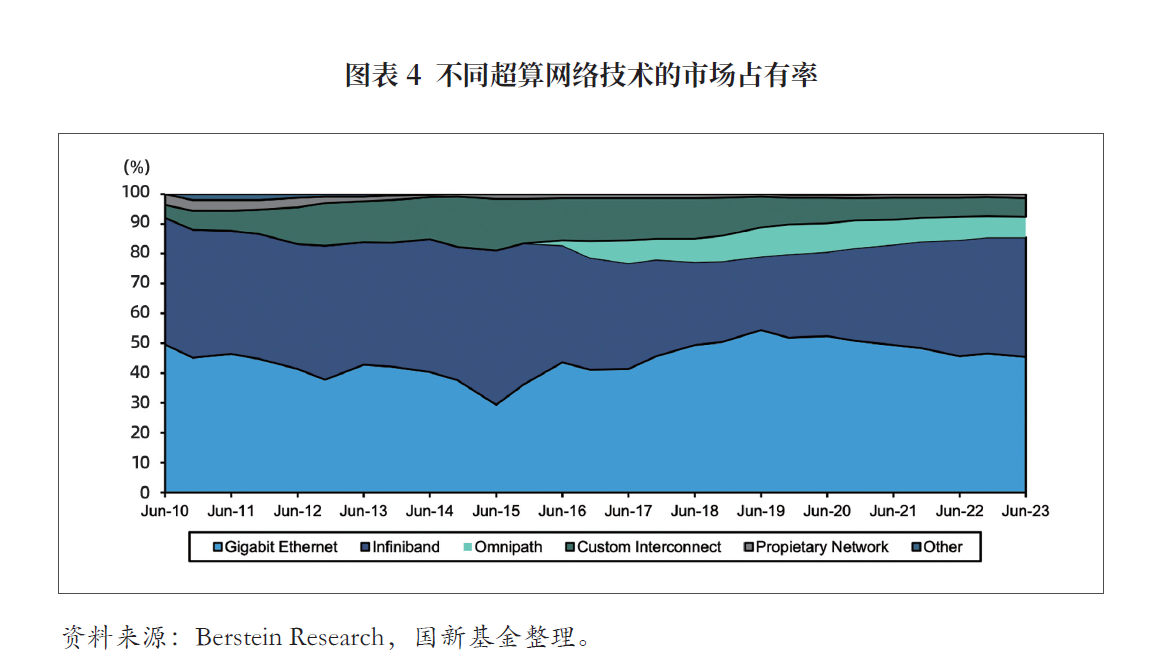
未来,随着ai集群和网络的扩展,预期以太网的使用可能更为广泛。许多超大规模数据中心已计划于ai基础设施中部署以太网,随着由推理驱动算力需求攀升,以太网网络或将因其生态的开放性获得更大发展空间,交换芯片生产商有望从ai基础设施的更广泛部署中受益。
三、相关机遇
(一)芯片内互连:重点关注chiplet
相较于传统消费级芯片,算力芯片面积更大,存储容量更大,对互连速度要求更高。采用chiplet既可以降低成本、提升良率,又可以允许装载更多计算核心,还便于引入hbm存储。chiplet技术的发展是延续芯片性能提升和创新的重要路径,代表了一种灵活、可扩展的集成电路设计和制造方法,对于整合新技术和生产高效、高性能的计算系统至关重要。持续的技术革新,包括新材料、3d堆叠和增强互连技术,将满足未来的计算需求,标志着soc和chiplet集成标准的重大进化。ai/ml/dl融入chiplet技术不仅有助于突破目前的技术限制,还为定制化设计、计算效率和快速创新解锁了新的可能性。
随着这些智能技术的不断发展,它们将显著影响chiplet的设计、制造和集成,推动下一代高性能计算系统的发展,建议关注利用人工智能技术进行chiplet仿真、设计、缺陷检测的公司。
(二)芯片间互连:国际层面关注头部公司替代产品,国内竞品从缺
虽然,目前中国和美国尚无完全匹配英伟达nvlink和nvswitch技术的直接竞品,但一些公司正在积极开发类似的高性能计算互连技术。amd的infinity fabric是一种高带宽、低延迟的互连技术,主要用于amd的gpu和cpu之间的通信,类似于nvidia的nvlink。通过与broadcom合作,amd正在开发accelerated fabric link(afl),计划在pcie gen7上扩展infinity fabric的应用。此外,ualink是一个由amd、intel、broadcom、cisco等公司支持的开放标准,旨在提供与nvidia nvlink竞争的高性能互连能力。
总体而言,随着高性能计算和ai训练需求的攀升,开发和采用这些新技术将是大势所趋。建议关注高性能计算和ai互连技术发展下的相关投资机会,如互连技术研发企业和高性能计算硬件供应商。
(三)高性能计算网络:关注以太网对infiniband网络的替代
生成式ai的高速渗透驱动了算力需求,构建规模更大、性能更强的数据中心已成为确定趋势。尽管infiniband在延迟等性能指标方面表现更好,但其价格更昂贵、耗电量更大,且多数情况下依赖英伟达作为供应商,而以太网在可扩展性、成本和功率方面具有优势,同时也受益于更开放的生态系统。在meta测试中,以太网组网价格不到infiniband的一半,且性能高出10%。
总体而言,随着由推理驱动算力需求攀升,以太网网络或将因其生态的开放性获得更大发展空间,交换芯片生产商有望从ai基础设施的更广泛部署中受益。建议关注ai以太网方案组网趋势下交换机、交换芯片、lpo光模块供应商等板块的投资机会。
(国新基金)
免责声明
本文的分析及建议所依据的信息均来源于公开资料,我们对这些信息的准确性和完整性不作任何保证,也不保证所依据的信息和建议不会发生任何变化。我们已力求文章内容的客观、公正,但文中的观点、结论和建议仅供参考,不构成任何投资建议。投资者依据文章提供的信息进行投资所造成的一切后果,概不负责。文章未经书面许可,任何机构和个人不得以任何形式翻版、复制和发布。如引用、刊发,需注明出处为国新资讯,且不得对文章进行有悖原意的引用、删节和修改。
- 工业母机数控系统 发展形势与相关建议2024-08-26
- 智能驾驶走向何方——高阶乘用车智能驾驶分析2024-08-26
- 新能源汽车产业 加速演进中的几个重要问题2024-08-13